 Information about the Apollo CPU and FPU. Information about the Apollo CPU and FPU. |
|
|---|
| | 
Stefan "Bebbo" Franke
Posts 142
29 Jun 2019 10:20
| I forgot to mention the modified handling of int constants:
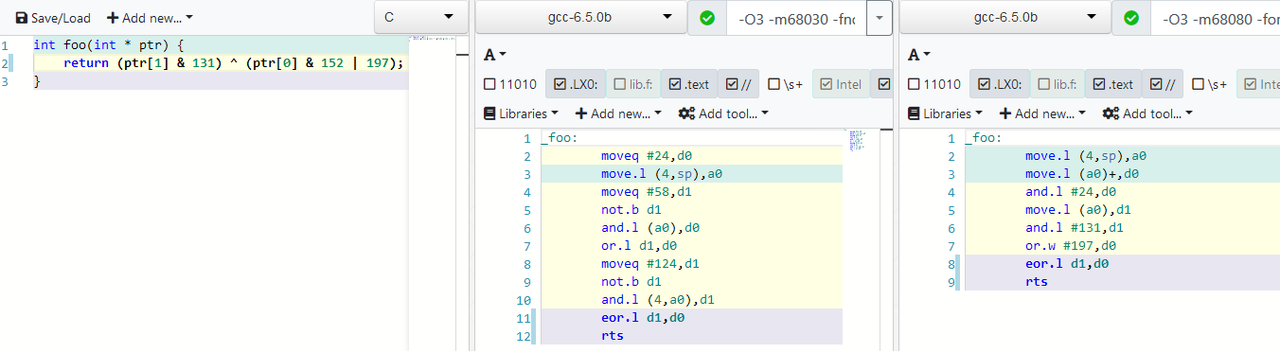
EXTERNAL LINK
| |
| | 
Gunnar von Boehn
(Apollo Team Member)
Posts 6254
29 Jun 2019 10:22
| Stefan "Bebbo" Franke wrote:
|
Which cpu - of the ones implemented in gcc - is the closest match and a good starting point?
Some cold fire? one of i386? mips? sparc? ...?
|
Not coldfire. (Coldfire FPU is slower than 68080) "Modern" FPU are pipelined like our.
E.g. Todays x86 (starting with Pentium), All PowerPC. Our goal should be to "inform" GCC that it can throw an FADD every cycle - but that each has a LATENCY..
Teaching GCC that running several FADD in parallem will increase speed a lot. For example, GCC does this very well for PowerPC.
| |
| |
Stefan "Bebbo" Franke
Posts 142
29 Jun 2019 11:27
| Gunnar von Boehn wrote:
|
Stefan "Bebbo" Franke wrote:
|
Which cpu - of the ones implemented in gcc - is the closest match and a good starting point?
Some cold fire? one of i386? mips? sparc? ...?
|
Not coldfire. (Coldfire FPU is slower than 68080)
"Modern" FPU are pipelined like our.
E.g. Todays x86 (starting with Pentium), All PowerPC.
Our goal should be to "inform" GCC that it can throw an FADD every cycle - but that each has a LATENCY..
Teaching GCC that running several FADD in parallem will increase speed a lot.
For example, GCC does this very well for PowerPC.
|
- how many float insns are processed parallel?
- what is the latency of each insn?
- is there a dependency of some insns to other insns? same for integer insn (disregard fusing here - 2 fused insns in 68080 should be treated as one insn in gcc)
- how many int insns are processed parallel?
--> 2
- what is the latency of each insn?
- is there a dependency of some insns to other insns? best is put dependand insns into groups and specify the dependency of the groups. e.g.
- indirect mem: blocks both pipes
- address used, is blocked by address calculation and so on... and for AMMX a capable GNU ASM is mandatory
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6254
29 Jun 2019 14:12
| Stefan "Bebbo" Franke wrote:
|
- how many float insns are processed parallel?
|
Please help me understand what is your definition of processed?
How many are in flight?
How many can be issued,
how many can be retired?
APOLLO 68080 can today issue/retire 1 FPU instruction per cycle.
Stefan "Bebbo" Franke wrote:
|
- what is the latency of each insn?
|
FMOVE 1
FADD 6
FSUB 6
FCMP 6
FMUL 6
FDIV 10
FSQRT 22
FMOVEM 1 per cycle
Inputformat which is float and comes from (Mem) (Dn) or FREG
== FREE
Inputformat which is TYPE INTEGER "+1 cycle" for any source
Stefan "Bebbo" Franke wrote:
|
- is there a dependency of some insns to other insns?
|
No
All calculations can be done in parallel.
Instruction which needs the FLAGS like
FBCC will wait for all instruction to finish.
Stefan "Bebbo" Franke wrote:
|
same for integer insn (disregard fusing here - 2 fused insns in 68080 should be treated as one insn in gcc)
- how many int insns are processed parallel?
|
2 INTEGER
(3 in some exception but lets ignored this today)
Stefan "Bebbo" Franke wrote:
|
- what is the latency of each insn?
|
always 1
More expensive are MUL=2
DIV=32
MOVEM=1 per Reg
MOVE16=4
CMPM=2
JMP/JSR with calculated EA =4 E.g. "JSR -40(A6)"
JMP /JSR absolute or PC-relativ =1
Stefan "Bebbo" Franke wrote:
|
- is there a dependency of some insns to other insns?
|
Both pipes can do memory access
but only 1 pipe can do it per cycle.
Flag dependency and Register dependency of course.
| |
| |
Stefan "Bebbo" Franke
Posts 142
29 Jun 2019 22:30
| I have no good example, but:
double foo(double a, double b, double c) {
return c/2 + c * (b-a) + b * b + a * (a + 1) / (a * a - 1);
}
yields now
_foo:
link.w a5,#0
fmovem #28,-(sp)
fdmove.d (8,a5),fp0
fdmove.d (16,a5),fp4
fdmove.x fp4,fp2
fdsub.x fp0,fp4
fdmove.x fp4,fp1
fdmove.d (24,a5),fp3
fdmul.x fp3,fp1
fdmul.d #0x3fe0000000000000,fp3
fdmul.x fp2,fp2
fdadd.x fp3,fp1
fdadd.x fp2,fp1
fmovecr #0x32,fp2
fdadd.x fp0,fp2
fdmul.x fp0,fp2
fmovecr #0x32,fp3
fdmul.x fp0,fp0
fdsub.x fp3,fp0
fddiv.x fp0,fp2
fdadd.x fp2,fp1
fmove.d fp1,-(sp)
move.l (sp)+,d0
move.l (sp)+,d1
fmovem (sp)+,#56
unlk a5
rts
would this be better?
_foo:
link.w a5,#0
fdmove.d (16,a5),fp0
fmovem #60,-(sp)
fdmove.d (8,a5),fp4
fdmove.x fp4,fp3
fmovecr #0x32,fp2
fdadd.x fp3,fp2
fdmul.x fp3,fp4
fdmul.x fp3,fp2
fdmove.x fp0,fp1
fdsub.x fp3,fp0
fmovecr #0x32,fp3
fdmove.d (24,a5),fp5
fdsub.x fp3,fp4
fddiv.x fp4,fp2
fdmul.x fp5,fp0
fdmul.d #0x3fe0000000000000,fp5
fdmul.x fp1,fp1
fdadd.x fp5,fp0
fdadd.x fp1,fp0
fdadd.x fp2,fp0
fmovem (sp)+,#60
fmove.d fp0,-(sp)
move.l (sp)+,d0
move.l (sp)+,d1
unlk a5
rts
| |
| |
Stefan "Bebbo" Franke
Posts 142
30 Jun 2019 21:40
| No feedback? Never mind. I put that change into the build queue -> if it does'nt break anything, it's live in 1 hour
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6254
30 Jun 2019 22:10
| Hi Bebbo, I think the code uses the parallelism already better.
So yes I think its an improvement. Thanks a lot. Maybe we can create other examples to discuss this better?
How about a workloop example which e.g. does a 3D rotation?
| |
| |
Stefan "Bebbo" Franke
Posts 142
01 Jul 2019 08:22
| Gunnar von Boehn wrote:
|
Hi Bebbo,
I think the code uses the parallelism already better.
So yes I think its an improvement. Thanks a lot.
Maybe we can create other examples to discuss this better?
How about a workloop example which e.g. does a 3D rotation?
|
Sorry, I'm not good at creating such examples.
Can someone else step in? (maybe even using EXTERNAL LINK )
| |
| | 
Steve Ferrell
Posts 424
01 Jul 2019 09:08
| Stefan "Bebbo" Franke wrote:
|
Gunnar von Boehn wrote:
|
Hi Bebbo,
I think the code uses the parallelism already better.
So yes I think its an improvement. Thanks a lot.
Maybe we can create other examples to discuss this better?
How about a workloop example which e.g. does a 3D rotation?
|
Sorry, I'm not good at creating such examples.
Can someone else step in? (maybe even using EXTERNAL LINK )
|
This C source loads and compiles: #include <stdio.h>
#include <math.h> #define M_PI 3.14159265358979323846264338327950288 typedef struct {
float x;
float y;
float z;
}Point;
Point points; float temp = 0; void showPoint() {
printf("%f %f %f\n", points.x, points.y, points.z);
} void translate(float tx, float ty, float tz) {
points.x += tx;
points.y += ty;
points.z += tz;
printf("After Translation, new point is :");
showPoint();
} void rotatex(float angle) {
angle = angle * M_PI / 180.0;
temp = points.y;
points.y = points.y * cos(angle) - points.z * sin(angle);
points.z = temp * sin(angle) + points.z * cos(angle);
printf("After rotation about x, new point is: ");
showPoint();
} void rotatey(float angle) {
angle = (angle * M_PI) / 180.0;
temp = points.z;
points.z = points.z * cos(angle) - points.x * sin(angle);
points.x = temp * sin(angle) + points.x * cos(angle);
printf("After rotation about y, new point is: ");
showPoint(); } void rotatez(float angle) {
angle = angle * M_PI / 180.0;
temp = points.x;
points.x = points.x * cos(angle) - points.y * sin(angle);
points.y = temp * sin(angle) + points.y *cos(angle);
printf("After rotation about z, new point is: ");
showPoint(); } void scale(float sf, float xf, float yf, float zf) {
points.x = points.x * sf + (1 - sf) * xf;
points.y = points.y * sf + (1 - sf) * yf;
points.z = points.z * sf + (1 - sf) * zf;
printf("After scaling, new point is: ");
showPoint();
} int main()
{
float tx = 0, ty = 0, tz = 0;
float sf = 0, xf = 0, yf = 0, zf = 0;
int choose;
float angle;
float my_x, my_y, my_z;
printf("Enter the initial point you want to transform: ");
scanf("%f %f %f", &my_x, &my_y, &my_z);
points.x = my_x; points.y = my_y; points.z = my_z;
printf("Choose the following: \n");
printf("1. Translate\n");
printf("2. Rotate about X axis\n");
printf("3. Rotate about Y axis\n");
printf("4. Rotate about Z axis\n");
printf("5. Scale\n");
scanf("%d", &choose);
switch (choose) {
case 1:
printf("Enter the value of tx, ty and tz: ");
scanf("%d %d %d", &tx, &ty, &tz);
translate(tx, ty, tz);
break;
case 2:
printf("Enter the angle: ");
scanf("%f", &angle);
rotatex(angle);
break;
case 3:
printf("Enter the angle: ");
scanf("%f", &angle);
rotatey(angle);
break;
case 4:
printf("Enter the angle: ");
scanf("%f", &angle);
rotatez(angle);
break;
case 5:
printf("Enter the value of sf, xf, yf and zf: ");
scanf("%f %f %f %f", &sf, &xf, &yf, &zf);
scale(sf, xf, yf, zf);
break;
default:
break;
}
return 0;
}
| |
| |
Steve Ferrell
Posts 424
01 Jul 2019 09:21
| This is probably more appropriate: #include <iostream>
#include <cmath>
using namespace std;
typedef struct {
float x;
float y;
float z;
}Point;
Point points;
float rotationMatrix[4][4];
float inputMatrix[4][1] = {0.0, 0.0, 0.0, 0.0};
float outputMatrix[4][1] = {0.0, 0.0, 0.0, 0.0};
void showPoint(){
cout<<"("<<outputMatrix[0][0]<<","<<outputMatrix[1][0]<<","<<outputMatrix[2][0]<<")"<<endl;
}
void multiplyMatrix()
{
for(int i = 0; i < 4; i++ ){
for(int j = 0; j < 1; j++){
outputMatrix[j] = 0;
for(int k = 0; k < 4; k++){
outputMatrix[j] += rotationMatrix[k] * inputMatrix[k][j];
}
}
}
}
void setUpRotationMatrix(float angle, float u, float v, float w)
{
float L = (u*u + v * v + w * w);
angle = angle * M_PI / 180.0; //converting to radian value
float u2 = u * u;
float v2 = v * v;
float w2 = w * w;
rotationMatrix[0][0] = (u2 + (v2 + w2) * cos(angle)) / L;
rotationMatrix[0][1] = (u * v * (1 - cos(angle)) - w * sqrt(L) * sin(angle)) / L;
rotationMatrix[0][2] = (u * w * (1 - cos(angle)) + v * sqrt(L) * sin(angle)) / L;
rotationMatrix[0][3] = 0.0;
rotationMatrix[1][0] = (u * v * (1 - cos(angle)) + w * sqrt(L) * sin(angle)) / L;
rotationMatrix[1][1] = (v2 + (u2 + w2) * cos(angle)) / L;
rotationMatrix[1][2] = (v * w * (1 - cos(angle)) - u * sqrt(L) * sin(angle)) / L;
rotationMatrix[1][3] = 0.0;
rotationMatrix[2][0] = (u * w * (1 - cos(angle)) - v * sqrt(L) * sin(angle)) / L;
rotationMatrix[2][1] = (v * w * (1 - cos(angle)) + u * sqrt(L) * sin(angle)) / L;
rotationMatrix[2][2] = (w2 + (u2 + v2) * cos(angle)) / L;
rotationMatrix[2][3] = 0.0;
rotationMatrix[3][0] = 0.0;
rotationMatrix[3][1] = 0.0;
rotationMatrix[3][2] = 0.0;
rotationMatrix[3][3] = 1.0;
}
int main()
{
float angle;
float u, v, w;
cout<<"Enter the initial point you want to transform:";
cin>>points.x>>points.y>>points.z;
inputMatrix[0][0] = points.x;
inputMatrix[1][0] = points.y;
inputMatrix[2][0] = points.z;
inputMatrix[3][0] = 1.0;
cout<<"Enter axis vector: ";
cin>>u>>v>>w;
cout<<"Enter the rotating angle in degree: ";
cin>>angle;
setUpRotationMatrix(angle, u, v, w);
multiplyMatrix();
showPoint();
return 0;
}
| |
| |
Stefan "Bebbo" Franke
Posts 142
01 Jul 2019 10:55
| Steve Ferrell wrote:
|
This is probably more appropriate:
...
void multiplyMatrix()
{
for(int i = 0; i < 4; i++ ){
for(int j = 0; j < 1; j++){
outputMatrix[j] = 0;
for(int k = 0; k < 4; k++){
outputMatrix[j] += rotationMatrix[k] * inputMatrix[k][j];
}
}
}
}
...
|
does not compile
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6254
01 Jul 2019 11:41
| How about we make it simple?
Please can you look at STREAM benchmark!
Its very popular and it is in fact a a FPU benchmark too.
EXTERNAL LINK
We should easily be able to measure and see the performance speed up.
Example:
#include <string.h>
void Scale(double scalar, double* b, double* c)
{
size_t j;
for (j=1000; j; j--){
*b++ = scalar * *c++;
}
}
And unrolled this one?
#include <string.h>
void Scale(double scalar, double* b, double* c)
{
size_t j;
for (j=1000; j; j--){
*b++ = scalar * *c++;
*b++ = scalar * *c++;
*b++ = scalar * *c++;
*b++ = scalar * *c++;
}
}
The online 6.5B compiler give my strange code for this.
It not uses FPU at all?
Can you help?
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6254
01 Jul 2019 13:23
| And how does this code look ?
#include <string.h>
void Scale(double scalar, double* b, double* c)
{
size_t j;
double t1;
double t2;
double t3;
double t4;
for (j=1000; j; j--){
t1 = scalar* *c++;
t2 = scalar* *c++;
t3 = scalar* *c++;
t4 = scalar* *c++;
*b++ =t1;
*b++ =t2;
*b++ =t3;
*b++ =t4;
}
}
| |
| |
Stefan "Bebbo" Franke
Posts 142
01 Jul 2019 13:25
| Gunnar von Boehn wrote:
|
How about we make it simple?
Please can you look at STREAM benchmark!
Its very popular and it is in fact a a FPU benchmark too.
EXTERNAL LINK
We should easily be able to measure and see the performance speed up.
Example:
void tuned_STREAM_Scale(STREAM_TYPE scalar)
{
ssize_t j;
#pragma omp parallel for
for (j=0; j<STREAM_ARRAY_SIZE; j++)
b[j] = scalar*c[j];
}
How does this compile?
|
this is a good example to show how hard it is to provide a good example. The result varies on the given options. It may yield:
tuned_STREAM_Scale(double):
rts
or
_tuned_STREAM_Scale:
link.w a5,#0
move.l a2,-(sp)
fdmove.d (8,a5),fp0
lea _c,a0
lea _b,a1
move.l #80000000,a2
add.l a0,a2
.L2:
fdmove.d (a0)+,fp1
fdmul.x fp0,fp1
fmove.d fp1,(a1)+
cmp.l a0,a2
jne .L2
move.l (sp)+,a2
unlk a5
rts
or do you want an unrolled loop?
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6254
01 Jul 2019 13:30
| Stefan "Bebbo" Franke wrote:
|
or do you want an unrolled loop?
|
Yes.
Can you please also compile the 3 snippest I posted above?Maybe we can also compare -OS and -O3
| |
| |
Stefan "Bebbo" Franke
Posts 142
01 Jul 2019 13:43
| Gunnar von Boehn wrote:
|
Can you help?
|
add -m68881 :-)
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6254
01 Jul 2019 13:47
| Lets look here
#include <string.h>
void Scale(double scalar, double* b, double* c)
{
size_t j;
double t1;
double t2;
double t3;
double t4;
for (j=1000; j; j--){
t1 = scalar* *c++;
t2 = scalar* *c++;
t3 = scalar* *c++;
t4 = scalar* *c++;
*b++ =t1;
*b++ =t2;
*b++ =t3;
*b++ =t4;
}
}
-Os -m68080 -mhard-float -fomit-frame-pointer
_Scale:
fmovem #28,-(sp)
fdmove.d (40,sp),fp0
move.l (48,sp),a0
move.l (52,sp),a1
clr.l d0
.L2:
fdmove.x fp0,fp3
fdmove.x fp0,fp2
fdmul.d (8,a1,d0.l),fp3
fdmove.x fp0,fp1
fdmul.d (16,a1,d0.l),fp2
fdmove.d (a1,d0.l),fp4
fdmul.x fp0,fp4
fdmul.d (24,a1,d0.l),fp1
fmove.d fp4,(a0,d0.l)
fmove.d fp3,(8,a0,d0.l)
fmove.d fp2,(16,a0,d0.l)
fmove.d fp1,(24,a0,d0.l)
add.l #32,d0
cmp.l #32000,d0
jne .L2
fmovem (sp)+,#56
rts
OK what could be improved? a) use LOOP which counts a D0 down
subq.l #1,D0
BNE.b b) GCC by accident used fat EA modes?
Does GCC calc the instruction length of this correctly?
(8,a0,d0.l) is 2 byte longer than
(a0)+ OK now use O3
_Scale:
fmovem #28,-(sp)
move.l a2,-(sp)
fdmove.d (44,sp),fp0
move.l (52,sp),a0
move.l (56,sp),a1
lea (32000,a0),a2
.L2:
fdmove.x fp0,fp4
fdmove.x fp0,fp3
fdmul.d (a1),fp4
fdmove.x fp0,fp2
fdmul.d (8,a1),fp3
fdmul.d (16,a1),fp2
fdmove.x fp0,fp1
lea (32,a1),a1
fdmul.d (-8,a1),fp1
fmove.d fp4,(a0)
fmove.d fp3,(8,a0)
fmove.d fp2,(16,a0)
lea (32,a0),a0
fmove.d fp1,(-8,a0)
cmp.l a0,a2
jne .L2
move.l (sp)+,a2
fmovem (sp)+,#56
rts
Again GCC uses EA (D16,A0) this is bigger and not faster than (a0)+
The code would be a lot better if (A0)+ is used.
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6254
01 Jul 2019 13:48
| Stefan "Bebbo" Franke wrote:
|
Gunnar von Boehn wrote:
|
Can you help?
|
add -m68881 :-)
|
68080 has FPU build in.
Can Hard-Fpu be default for it?
| |
| |
Stefan "Bebbo" Franke
Posts 142
01 Jul 2019 13:49
| Gunnar von Boehn wrote:
|
First: you can't unroll-loops with -Os^^
And how does this code look ?
#include <string.h>
void Scale(double scalar, double* b, double* c)
{
size_t j;
double t1;
double t2;
double t3;
double t4;
for (j=1000; j; j--){
t1 = scalar* *c++;
t2 = scalar* *c++;
t3 = scalar* *c++;
t4 = scalar* *c++;
*b++ =t1;
*b++ =t2;
*b++ =t3;
*b++ =t4;
}
}
|
this code can be scheduled: EXTERNAL LINK
_Scale3:
link.w a5,#0
fmovem #28,-(sp)
move.l a2,-(sp)
fdmove.d (8,a5),fp0
move.l (16,a5),a0
move.l (20,a5),a1
lea (32000,a0),a2
.L2:
fdmove.x fp0,fp4
fdmove.x fp0,fp3
fdmul.d (a1),fp4
fdmove.x fp0,fp2
fdmul.d (8,a1),fp3
fdmul.d (16,a1),fp2
fdmove.x fp0,fp1
lea (32,a1),a1
fdmul.d (-8,a1),fp1
fmove.d fp4,(a0)
fmove.d fp3,(8,a0)
fmove.d fp2,(16,a0)
lea (32,a0),a0
fmove.d fp1,(-8,a0)
cmp.l a0,a2
jne .L2
move.l (sp)+,a2
fmovem (sp)+,#56
unlk a5
rts
the shorter ones won't work for now - since the scheduler is feed with single (gcc internal) insns like
fmul (a0),(a1)
it might help to split those insns in a prepent pass...
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6254
01 Jul 2019 14:01
| Did you saw my post reporting that unneeded longer EA modes are used?
How could this happen with -Os
| |
|
|
|


