 Performance and Benchmark Results! Performance and Benchmark Results!
|
| Sinnlose Performance | page 1 2
|
|---|
|
|---|
| | 
Gunnar von Boehn
(Apollo Team Member)
Posts 6222
25 Oct 2019 23:10
| Extrem Performance
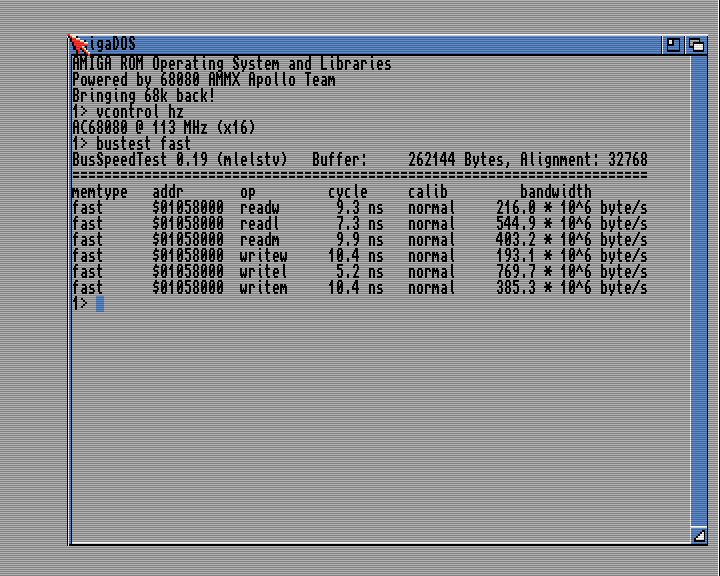
| |
| | 
Cyprian K
Posts 26
26 Oct 2019 00:14
| really nice figures.
I wonder why readm/writem (movem I guess) is slower than readl/writel
| |
| | 
Bernd Meyer
Posts 6
26 Oct 2019 05:43
|
I wonder why readm/writem (movem I guess) is slower than readl/writel
|
Because it is a little closer to the truth. From the README for bustest (emphasis added):
Method: determine a chunk of memory and time read and write operations with the
pretty exact CIA timers. After that the overhead of the measurement is
compensated.
|
That's a very bad idea indeed for any desktop processor released in the last quarter century. Back in the 68000 days, the memory interface was simply one aspect of the main ALU; The external memory interface only started accessing the memory when the instruction made it to the ALU, and the ALU (and thus the CPU) would not move on until the memory access was completed. So compensating for the overhead of getting the instructions to the ALU made some sense back then, and bustest does so by measuring both memory-to-register (or register-to-memory) operations as well as the same routines using equivalent register-to-register operations instead, and then attributing the only difference to memory access. This all goes awry once you add caches, because they decouple the memory interface from the ALU, having both run in parallel. So during the time needed to line up the memory instructions to the ALU, the memory interface is busy talking to the external memory. Which means that compensating for this "overhead" is the wrong thing to do, because it over-reports actual interface bandwidth. Because the MOVEM-based tests in bustest transfer 128 bytes with 6 instructions (4 transfers, a SUB, and a BNE), the compensation is comparatively small. The MOVE.L based tests, instead, transfer the same amount using 34 instructions (32 MOVEs, SUB and BNE), and thus there is considerably more "free" time during which the memory interface is working. Of course, all of these issues only get worse when you add speculative prefetching, multiple execution units, and especially out-of-order execution. Which is why in 2019, the only memory benchmark that makes any sense is one that actually reports how much memory it transferred in a given time; Anything that reports how much memory it could have moved if concentrating 100% on it, but didn't, is bound to be meaningless. (And there is also an issue with Gunnar's results coming from a 256k block, and the V4's Cyclone V A5 having about 512kB of embedded M10K memory; So to what extent this test actually hit the main memory at all is uncertain, given that a lot of that memory may well be used for data cache)
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6222
26 Oct 2019 09:02
| Bernd incorrectly assumed a few things and therefore some reasonings are not correct. Let us help here and explain all this:
a)First of all: The results are fully real.
APOLLO is by far the most powerful 68K CPU and even beats with ease Gigaherz PPC systems in such tests.
APOLLO 68080 is can really write ~ 800 MB/sec to the main memory.
And this with just ~ 100 MHz clock rate.
When running the test with bigger size e.g. 8 MB the result does stay the same.
If you know how memory interfaces work,
then you easily see this yourself on the scores as the READ is slower than the WRITE.
This clearly indicates real memory access and not caches hits.
On cache hits both would have the same score or READ would be better.
b) That "SUB / BNE" has any impact to the test,
or that "SUB/BNE" would slow the test down
- his an incorrect assumption for Apollo.
The reason is simple, that APOLLO 68080 is a super-scalar CPU
and that APOLLO can do these extra instructions for free in parallel.
c) The result is very easy to understand when you look
at the used instructions in the test and the CPU clockrate.
The test program does 32bit = 4 Byte transfers.
APOLLO 68080 is a 64bit CPU but the test is NOT a 64bit test.
The test does 32bit operation.
32bit = 4 Byte.
4 Byte * 100 MHz == 400 MB/sec.
This means the very best a 32bit CPU with 100 MHz can score in this test will be 400 MB/sec.
As you all know APOLLO 68080 is a 64bit CPU,
has 64bit Registers, has 64Bit Caches, and has 64bit Memory Interface.
The Apollo CPU can sometimes "rewrite old 32bit" code to become 64bit code.
The Apollo CPU does this internally and automatically.
This means it can by itself make old code run much faster.
The CPU does this is a number of conditions are fulfilled.
It monitors if two memory access are sequential,
and if both memory access are in "normal fastmem" but not in IO space. If all "rules" are fulfilled, then the CPU can "merge" such access and create 64bit code internally.
64bit=8Byte
8 Byte * 100 MHz == 800 MB/sec.
With 64bit code the maximum score our Core at 100MHz can reach is 800MB/sec.
As you see in the result Apollo was able to upgrade two of the six tests in the program to 64bit access automatically.
Lets look at the used instruction in 3 tests:
1) MOVE.W moves 2 Byte per access
2) MOVE.L moves 4 Byte per access
3) MOVEM.L moves 4 Byte per access
This means the best possible score at 100 MHz would be
2* 100 = 200
4* 100 = 400
4* 100 = 400
Now Apollo was able to fuse "2 MOVE.L" into "1 MOVE.Q"
Allowing it to increase the limit to 800 MB/sec.
I hope my explanation was not to technically
and will help you to understand the scores better. :-D Memory performance is a very important factor of real live performance. Many programs and applications depend on memory performance. APOLLO 68080 is highly tuned for good memory performance.
And the good memory performance is part of the reason why AMIGA OS runs so super fast on the Vampires.
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6222
26 Oct 2019 09:39
|  Lets see the impact of the size of the copied block.
Test 1) 128 KB
Test 2) 8 MB
| |
| |
Cyprian K
Posts 26
26 Oct 2019 10:05
| that's clear now Gunnar. cool optimisation.
What about instruction e.g. "movem.l (A6),D0-D7", will it be also 64bit optimised?
| |
| |
Bernd Meyer
Posts 6
26 Oct 2019 10:37
| Gunnar von Boehn wrote:
|
Bernd incorrectly assumed a few things(...)
a)First of all: The results are fully real.
APOLLO 68080 is can really write ~ 800 MB/sec to the main memory.
|
I don't know whether it can write 800MB/s (or even 770MB/s) to main memory. I do know that it did not do so in this particular test.
It's easy --- bustest times how long it takes to write a certain amount of data to main memory, and then subtracts the time it takes to write the same amount of memory to registers, using the same number of instructions. You know this.
The innermost loop for the WRITEL test looks like this:
MOVE.W D1,(A0)+ <-- repeats 32 times
SUBQ.L #1,D0
BNE -68
IF the transfer rate was actually 770MB/s, then each time through the loop would take 166ns.
However, in reality, 166ns is the difference between how long it took to run one iteration of that loop and how long it took to run one iteration of the "overhead measurement" loop:
MOVE.W D2,D3 \ 16 repeats of
MOVE.W D4,D5 / this pair of instructions
SUBQ.L #1,D0
BNE -68
So the actual time it took for the memory writing loop is 166ns plus however long that compensation loop took. Given that the 68080 core has only two integer execution engines, those 16 repeats take at least one clock cycle each, and at least one extra for the SUBQ and BNE combined. Which means that at 113MHz (it says so in your own screenshot), there are at least an extra 150ns (17 clock cycles).
So based on the shown bustest result, we know that actual transfer rate in the WRITEL test is at most 128 bytes per 316ns (166ns "measured", plus 150ns incorrectly "compensated"). Which is 405MB/s, very close to the value reported for the WRITEM test, which suffers much less from the last-century-appropriate "compensation".
then you easily see this yourself on the scores as the READ is slower than the WRITE.
This clearly indicates real memory access and not caches hits.
|
Except for WRITEM/READM, that isn't actually the case.
Memory performance is a very important factor of real live performance. Many programs and applications depend on memory performance.
|
Indeed. Which is why you should really measure it with something which doesn't make assumptions which haven't been true since C= went under.
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6222
26 Oct 2019 11:24
| Bernd Meyer wrote:
|
I don't know whether it can write 800MB/s (or even 770MB/s) to main memory. I do know that it did not do so in this particular test.
|
Do I understand you right,
that your claim here is base on your privat assumption
that BUSTEST in general calculates wrong
and that all scores which are ever measured by BUSTEST
for all 68k AMIGAs, all Accelerators, and all PPC Computers is incorrect?
This would mean, that you also think that all BUSTEST results even for 68060 Accelerators are the same way wrong?
Your assumption is based on what exactly?
On your study of the program,
and measurements you did on 68060 CPUs,
or on your interpretation of the readme?
We can remotely not easily review the code here.
We can talk here about instructions and cycles and this will be complex to understand but maybe we can solve this
very easily with MATH and LOGICAL thinking?
Let me ask you some simple question:
What is in your opinion the Speed, the APOLLO CPU should be able to reach in those 3 tests when accessing the DCACHE?
We can with logic very easily calculate this.
And if BUSTEST calcs really wrong then those scores would be wrong too.
And we can very easily verify this. :-D
If what you say would be correct, then BUSTEST would calc wrong in those MOVE.L test also on any other CPU.
This means BUSTEST would report impossible values for 68060 too?
And for testsizes which hit the cache on 060 it would score impossible values too?
And this is also very easy to verify.
A 68060 CPU @ 50MHz can do 4 Byte per cycle on Cache hit.
This means these test will score best case
50*4 = 200 MB/sec on a 68060 CPU.If you run "BUSTEST fast size=2K" on an 68060 you will have 100% cache hitrate. Bernd, if your claim is right that BUSTEST just calcs wrong then BUSTEST would reach not 200 MB/sec for the 68060 here but mmuch more for example 400 MB/sec. Everyone can easily verify this himself and doublecheck your assumption.
| |
| |
Bernd Meyer
Posts 6
26 Oct 2019 12:06
| Gunnar von Boehn wrote:
| | Do I understand you right,
(...)
and that all scores which are ever measured by BUSTEST
for all 68k AMIGAs, all Accelerators, and all PPC Computers is incorrect?
|
No, bustest is doing something that was very reasonable on the 68000 and 68020, became problematic on the 68030, even more so on the 68040, and became outright silly on the 68060 and beyond.
This would mean, that you also think that all BUSTEST results even for 68060 Accelerators are the same way wrong?
|
Indeed. However, actual 1990-ies 68060 accelerators had comparatively slow (1990-ies) RAM, so there is an order of magnitude difference between the time taken by the compensation routine and the time actually taken in the memory-accessing routines. So the erroneous compensation only adds 10 to 20 percent. In contrast, the Vampire has RAM from the 2010s, which is an order of magnitude faster, whereas the IPC on the compensation routine is unchanged, and clock speed is only about twice faster. So now the ratio is roughly 1:1, and compensation adds roughly 100%.
Your assumption is based on what exactly?
On your study of the program,
|
Yes. Except it's not an "assumption", but a fact.
We can remotely not easily review the code here.
|
Why not? Surely you have a disassembler available? Even if not, you could just trust someone who does this sort of analysis for a living....
Let me ask you some simple question:
What is in your opinion the Speed, the APOLLO CPU should be able to reach in those 3 tests when accessing the DCACHE?
|
How the hell should I know? AFAICT, there has been exactly zero publicly available information about the cache architecture in the 68080, apart from it being a Harvard architecture (i.e. separate instruction and data cache).
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6222
26 Oct 2019 12:12
| Bernd Meyer wrote:
|
Gunnar von Boehn wrote:
|
Let me ask you some simple question:
What is in your opinion the Speed, the APOLLO CPU should be able to reach in those 3 tests when accessing the DCACHE?
|
How the hell should I know? AFAICT, there has been exactly zero publicly available information about the cache architecture in the 68080, apart from it being a Harvard architecture (i.e. separate instruction and data cache).
|
Lets make it very simple.
Answer this for the 68060 and run BUSTEST for the DCache hit case on 68060.
As said a 50 MHz 68060 will score 200 MB/sec for DCache hit.
You can easily verify this yourself, and doublecheck if your assumption is a fact or not.
| |
| |
Bernd Meyer
Posts 6
26 Oct 2019 13:04
| Gunnar von Boehn wrote:
| | Lets make it very simple.
Answer this for the 68060 and run BUSTEST for the DCache hit case on 68060.
As said a 50 MHz 68060 will score 200 MB/sec for DCache hit.
You can easily verify this yourself, and doublecheck if your assumption is a fact or not.
|
Sure. That's because bustest will actually use a (mostly) sensible compensation when reading/writing sub-cache-sized blocks. Once again, this is clear from the bustest README:
If you increase the size you see partial cache trashing caused by
interrupts that reduce the effective bandwidth. Also, in this case
bustest cannot effectively compensate overhead but shows a less
precise estimate (calib == "biased")
|
Why don't you explain why you think the WRITEM result is so much lower than the WRITEL result? And once you have explained that, why don't you then run the test on the 68080 with size=2k?
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6222
26 Oct 2019 13:10
| Lets clear this up. Let us look at 68060 results.
We have here an 68060 CPU clocked at 50 MHz.
The math we want to proof is: 4 Byte *50 MHz== 200 MB/sec
If Bustest calculates correctly then it will measure around 200 MB/sec for the size=1k and size=2k cases.
Bernie, if Bustest math is totally wrong as you claim it would be,
then BUSTEST would measure over 200 MB/sec, probably around 300-400 MB/sec or so.
Here is the result:

We can clearly see that BUSTEST calculates correctly.Bernei, do you agree that your assumption and claim that BUSTEST being wrong is clearly unfounded?
We can also see how much better
the memory performance of Apollo 68080 is compared to 68050@50MHz.
The Vamp is scoring like 30 times better then 68060 in some results. Do we all agree on this verification now?
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6222
26 Oct 2019 13:52
| Bernd Meyer wrote:
|
Why don't you explain why you think the WRITEM result is so much lower than the WRITEL result? And once you have explained that, why don't you then run the test on the 68080 with size=2k? |
I clearly explained this before.
Just scroll up and reread it. Let me help you again and quote myself:
4 Byte * 100 MHz == 400 MB/sec.
This is the expected score for the 32bit Bustest code.As you all know APOLLO 68080 is a 64bit CPU,
has 64bit Registers, has 64Bit Caches, and has 64bit Memory Interface.
The Apollo CPU can sometimes "rewrite old 32bit" code to become 64bit code.
The Apollo CPU does this internally and automatically.
This means it can by itself make old code run much faster.
The CPU does this is a number of conditions are fulfilled.
It monitors if two memory access are sequential,
and if both memory access are in "normal fastmem" but not in IO space. If all "rules" are fulfilled, then the CPU can "merge" such access and create 64bit code internally.
64bit=8Byte
8 Byte * 100 MHz == 800 MB/sec.
With 64bit code the maximum score our Core at 100MHz can reach is 800MB/sec.
As you see in the result Apollo was able to upgrade two of the six tests in the program to 64bit access automatically.
Lets look at the used instruction in 3 tests:
1) MOVE.W moves 2 Byte per access
2) MOVE.L moves 4 Byte per access
3) MOVEM.L moves 4 Byte per access This means the best possible score at 100 MHz would be
2* 100 = 200
4* 100 = 400
4* 100 = 400
Now Apollo was able to fuse "2 MOVE.L" into "1 MOVE.Q"
Allowing it to increase the limit to 800 MB/sec.
|
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6222
26 Oct 2019 14:02
| Bernd Meyer wrote:
|
why don't you then run the test on the 68080 with size=2k?
|
And I can also provide you this numbers:

The APOLLO 68080 runs a little bit over 113 MHz
So the expected Cache hit scores are
READ WORD = 114*2
READ LONG = 114*8
READ MULT = 114*4
And this is exactly what BUSTEST measures.
As you see BUSTEST is very accurate.
For the WRITE the scores are of course affected by the outside memory - as APOLLO runs the fast memory in coherent - write through mode.
And as you can clearly see,
APOLLO reaches awesome 800 MB/sec memwrite on this x16 core.
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6222
26 Oct 2019 14:34
| Cyprian K wrote:
|
that's clear now Gunnar. cool optimisation.
What about instruction e.g. "movem.l (A6),D0-D7", will it be also 64bit optimised?
|
No not as today.
The MOVEM.L runs today iteratively.
This explains the score of MOVEM.
If it would also be "merged" then this test would also score ~ 800 MB/sec.I agree with you that tuning this could been evaluated to increase APOLLO speed even more.
| |
| |
Bernd Meyer
Posts 6
26 Oct 2019 14:51
|
I clearly explained this before. Just scroll up and reread it.
|
So you are saying the 68080 core does combine two writes from separate instructions, but does not combine multiples writes from the same instruction? That is an, uhm, odd choice....
Gunnar von Boehn wrote:
|
APOLLO reaches awesome 800 MB/sec memwrite on this x16 core.
|
You keep telling yourself that...
But given that you are now selling stuff, and postings/statements like this could be seen as advertising, and false advertising has the potential to cause you a lot of pain, I'd really recommend you do some real benchmarking with programs which are suitable for the thing you are trying to benchmark.
Because, and I only use this word because you did so recently towards my work, what you are doing here is cheating.
It's not that hard to write a program which writes 10GB to memory, and time it with a stop watch. Or just consider that you are using a single 16 bit DDR3 chip with write latency 5 and max burst length of 8 on a 400MHz bus, and think about how long one write burst takes with those parameters, how many bytes it transfers, and what throughput that translates to.
(Oh, and I'd be interested in the results for a 2k blocksize run. For the one you posted earlier, you left out the 'k')
| |
| | 
Pedro Cotter
(Apollo Team Member)
Posts 308
26 Oct 2019 15:15
| Sorry to interrupt guys... Bernd are you the Amithlon/UAE Jit Bernie? :)
| |
| |
Gunnar von Boehn
(Apollo Team Member)
Posts 6222
26 Oct 2019 15:29
| Bernd Meyer wrote:
|
Or just consider that you are using a single 16 bit DDR3 chip with write latency 5 and max burst length of 8 on a 400MHz bus,
|
Why did you guess the MHz value of our memory?
I did not tell you this value.
So why are you guessing here? (wrongly)Why do you talk about write-latency 5?
Write latency has zero impact on the write throughput.
Why do you refer a meaningless value? What exactly is your point Bernd?
What are you trying to say?
That the memory chip could do more?
Yes, it could do more.
But the CPU writes ~ 770 MB/sec.
And we tested this with many benchmarks and not just with this.
And we can "see" bus saturation counters inside our memory controller. We know that this value is 100% correct.
I'm puzzled that you challenge the truth here?
Why do you do this?
Bernd, lets be honest here and look what you posted so far. A) You claimed the 770 MB/sec value would be wrong.
You basically said the truth would 50% of this.
Your claim was incorrect.
B) You claimed that BUSTEST is known to miscalc this test.
Another unproven and incorrect claim.
C) You supported your claim with some "math values".
The math values you posted were not matching the reality as shown with 060 scores.
D) You argued that 68080 scores will be wrong as already the 68060 scores are known to be wrong.
Again an unproven and incorrect claim.
When I read you post - they look to me like false claims.
But I assume this must be misunderstanding as your goal certainly
can not be, just to come here and to post false claims, can it?
Bernd, please help me understand what you goal is and what you try to say.
| |
| | 
Samuel Devulder
Posts 248
26 Oct 2019 16:11
| Gunnar von Boehn wrote:
|
This explains the score of MOVEM.
If it would also be "merged" then this test would also score ~ 800 MB/sec.
I agree with you that tuning this could been evaluated to increase APOLLO speed even more.
|
As we all know, many (not to say all) subroutines have a prologue and an epilog consisting in MOVEM to protect locally used regs onto the stack. If the speed of the movem could be reduced by 2 (eg saving N regs only costs N/2 cycles), it would have a major impact over most of the subroutines, and hence most programs to be run on the apollo core. This might be a very welcome optimisation to have.
| |
| | 
Nixus Minimax
Posts 416
26 Oct 2019 17:21
| Merging two writes from two subsequent instructions is easier than doing the same for two writes from a single instruction because the two instructions will simply be overwritten with the 64bit move instruction in the instruction queue. This can't be done with the MOVEM as it will almost always have more than two source registers to move. I'm not even willing to think about uneven numbers of registers to move...
| |
|
|
|


